Ship Better Search
with Confidence.
The all-in-one evaluation platform for search and ML teams. Mix human raters and AI Judges to track NDCG, compare ranking models, and build datasets for Learning-to-Rank. Use our cloud platform or self-host the open-source edition.

Works seamlessly with your stack
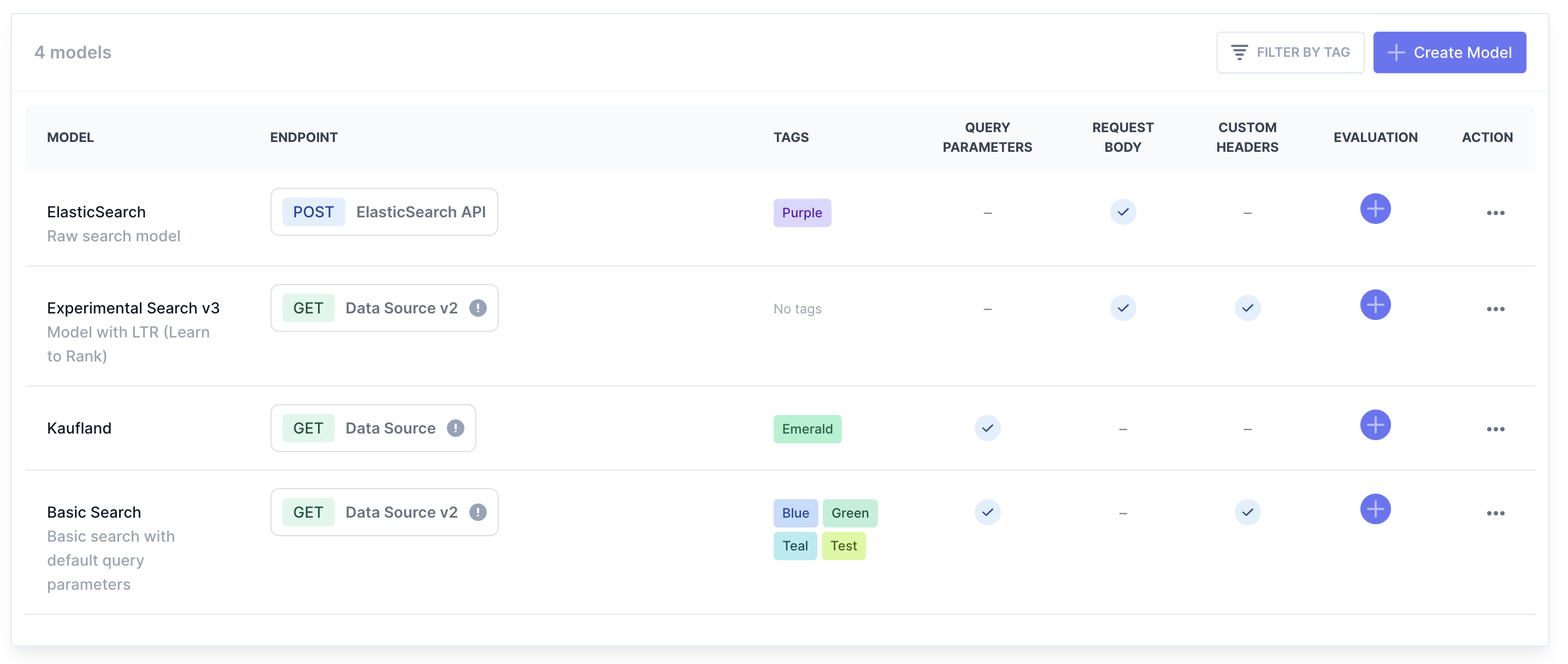
Step 1: Connect & Configure
Stop hardcoding test scripts.
SearchTweak securely connects to your API infrastructure. Fully proxy requests, parse JSON responses with custom code, and test ranking changes in seconds.
No more fragile config files. Define your endpoints and mapper code right in the UI to rapidly experiment with new search models.
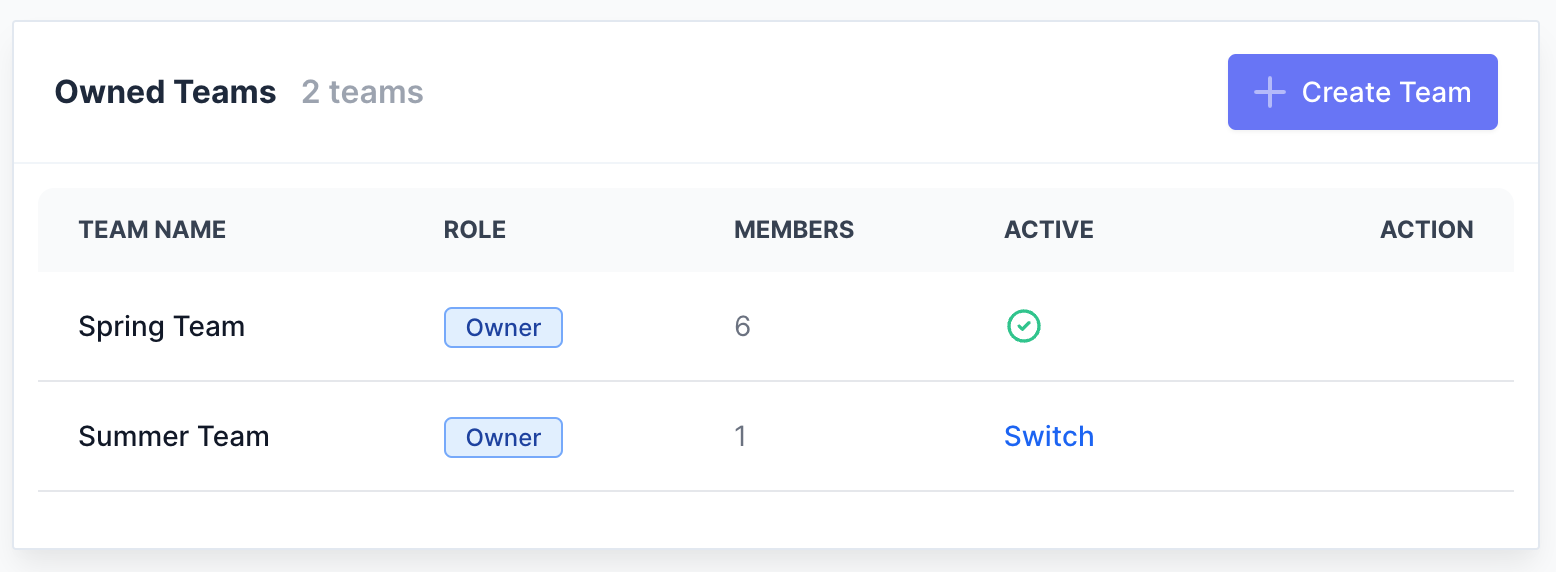
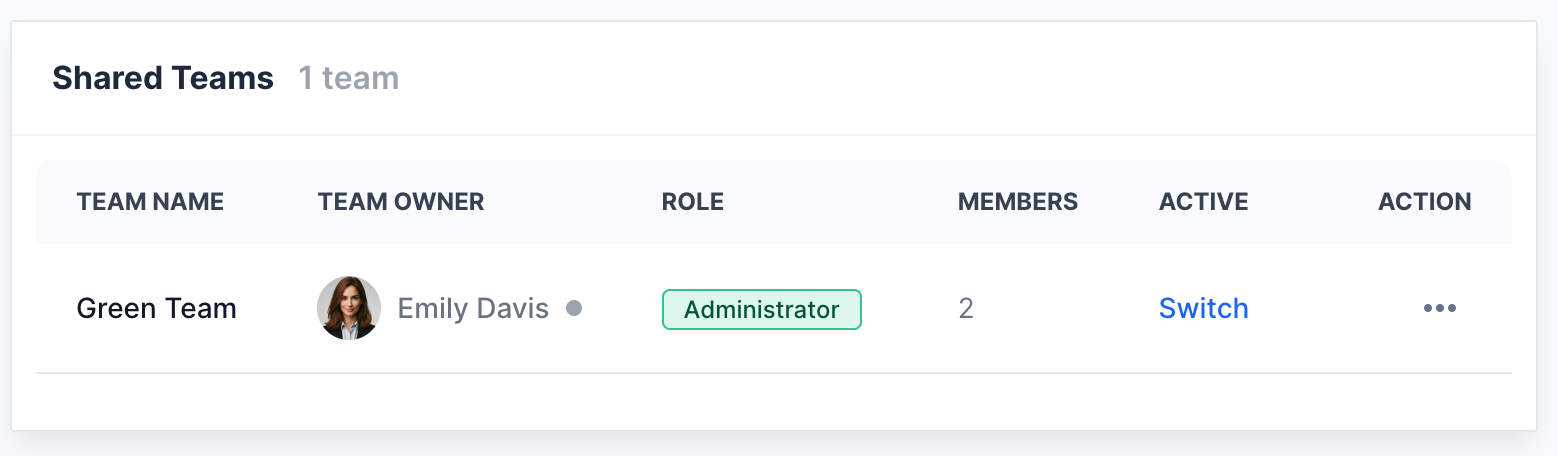
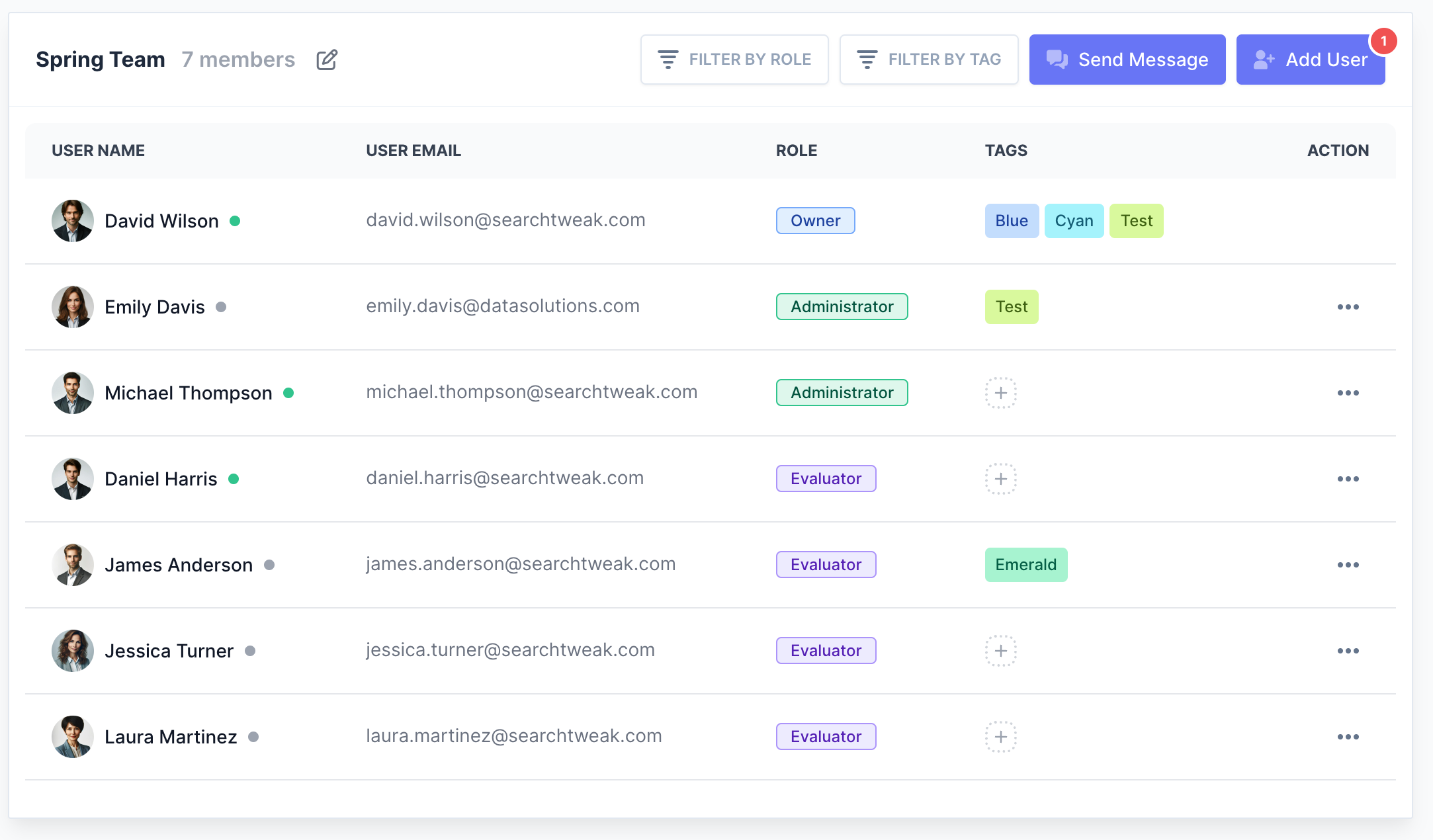
Collaborate like a pro
Bring your ML engineers, Product Managers, and human raters into a single workspace. Organize tasks with tags and roles to keep everyone aligned.
Stop sharing evaluation spreadsheets. Manage teams, distribute tasks, and analyze evaluation results in one centralized platform.
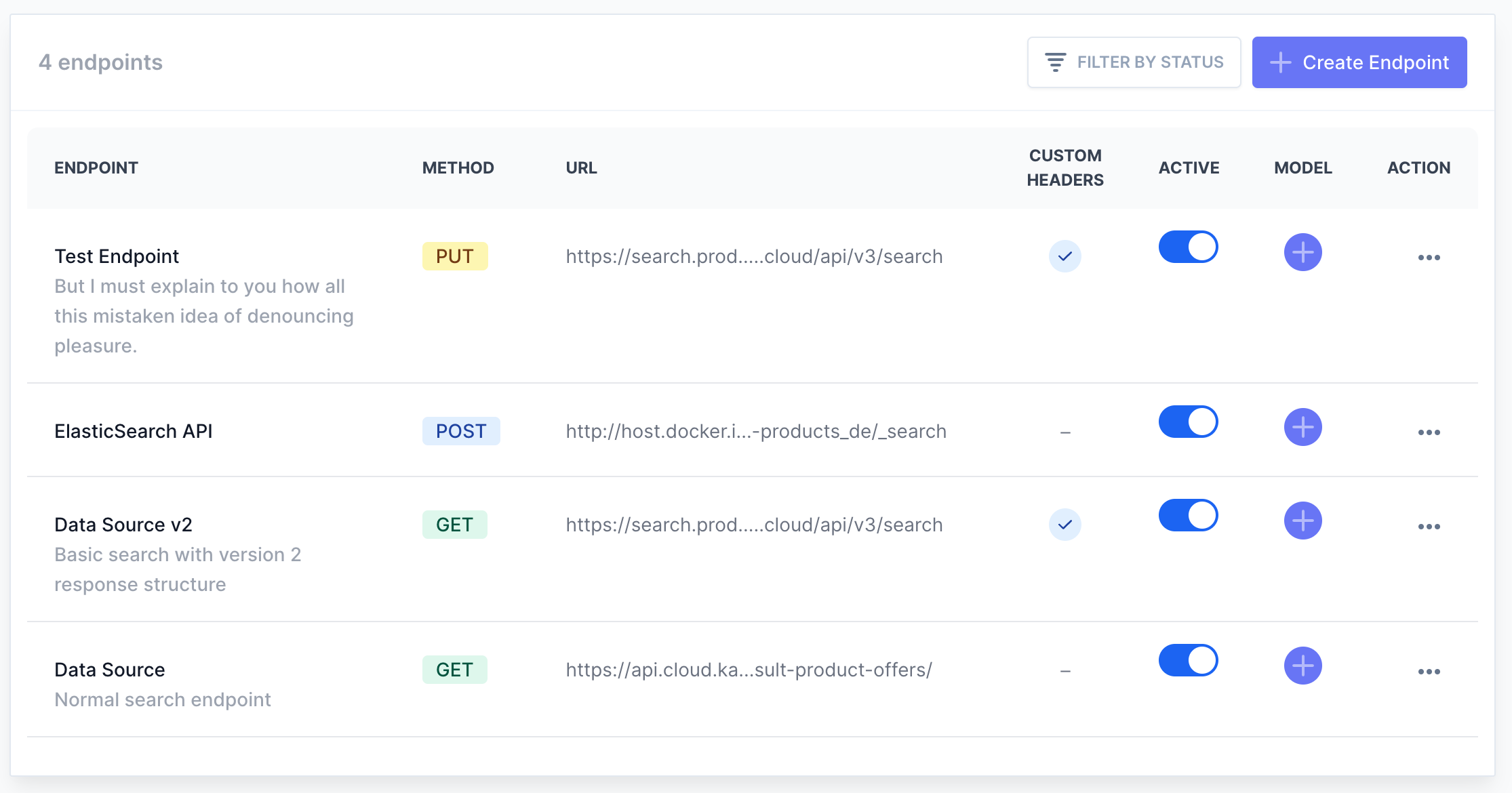
Built for any search engine
Bring your own stack. We handle the integration complexity so you can focus entirely on search relevance tuning.
- Avoid CORS issues with fully proxyable requests
- Extract nested payload attributes via mapper code
Step 2: Evaluate at Scale
Combine human precision with AI scale
Scale labeling with LLMs. Run large batches and merge AI judgments with human feedback in a single workflow. Evaluate new ranking models instantly to slash time-to-production.
- Multi-provider support (OpenAI-compatible, Anthropic, Gemini, DeepSeek, Groq, xAI, Ollama)
- Prompt templates per scale (Binary, Graded, Detail) and advanced model params
- Full auditability: run status, logs, token usage, and JSONL export
Use AI for throughput and humans for quality control. This hybrid loop lets you validate changes faster with zero risk.
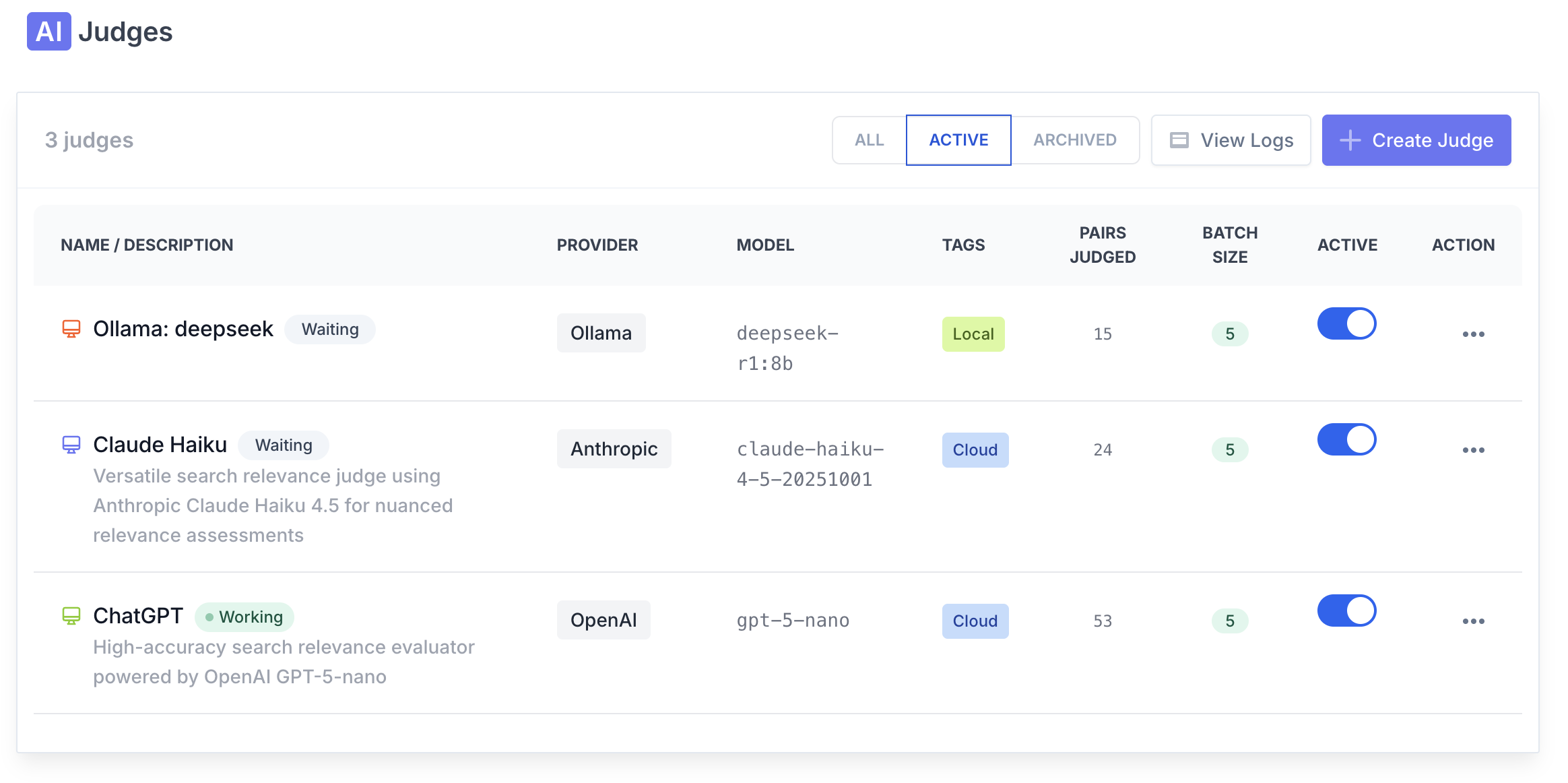
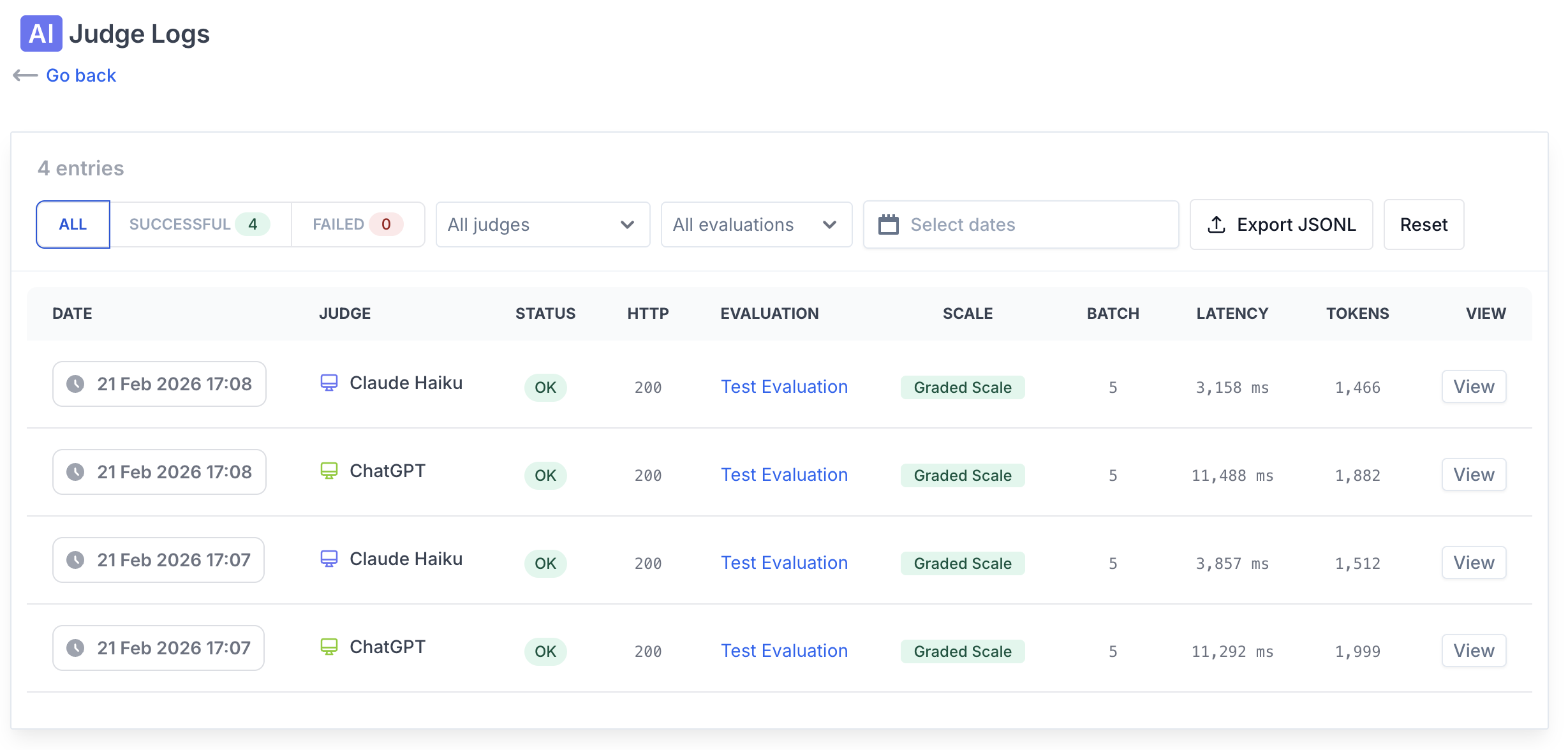
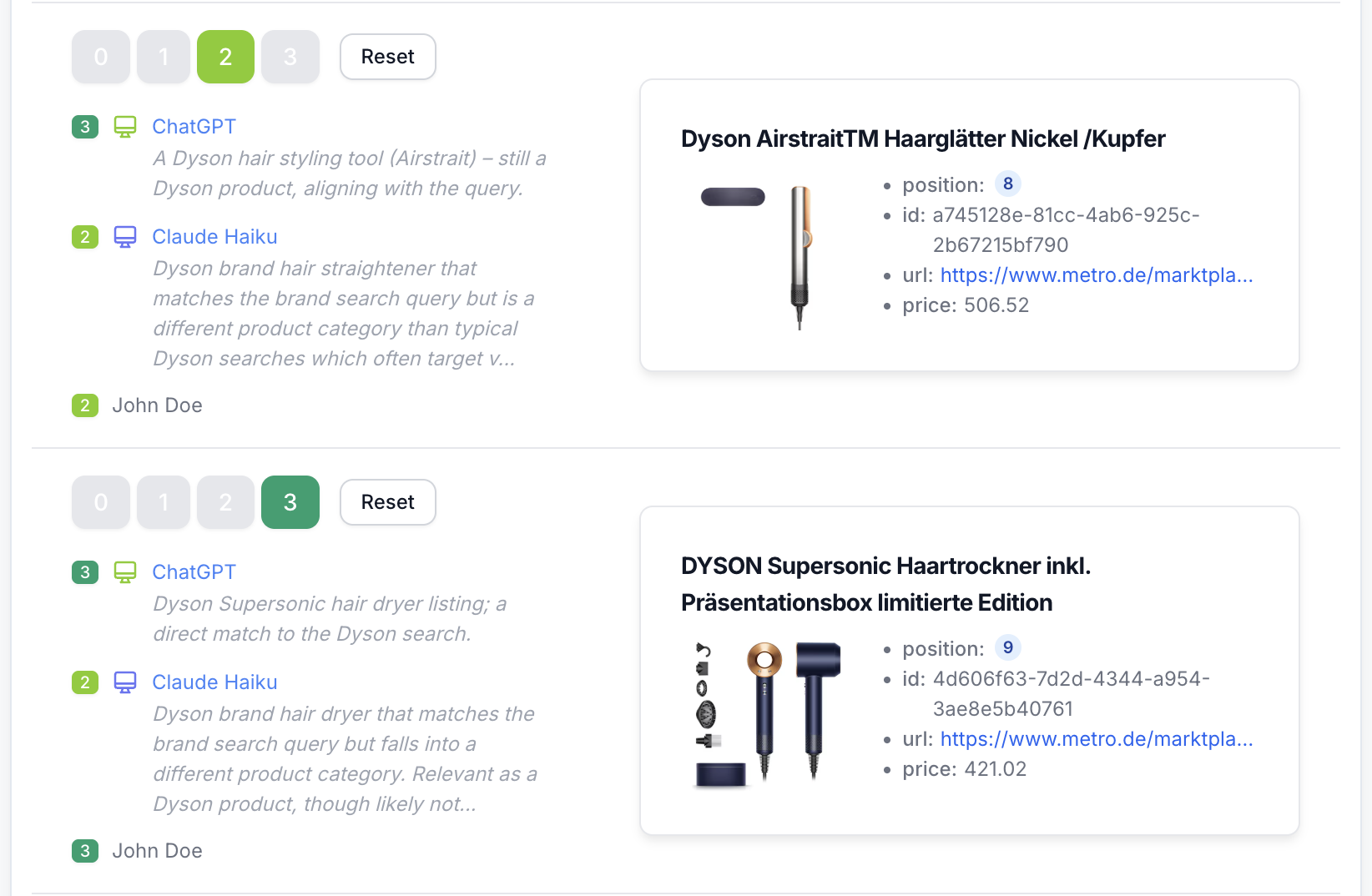
Reasoned AI scoring
AI scoring shouldn't be a black box. Each judge returns a concise reason alongside its label, making evaluations easy to review and discuss.
Audit score changes instantly, resolve disagreements with human raters, and refine your grading prompts over time.
- Score + reason per query-document pair
- Faster error analysis and calibration
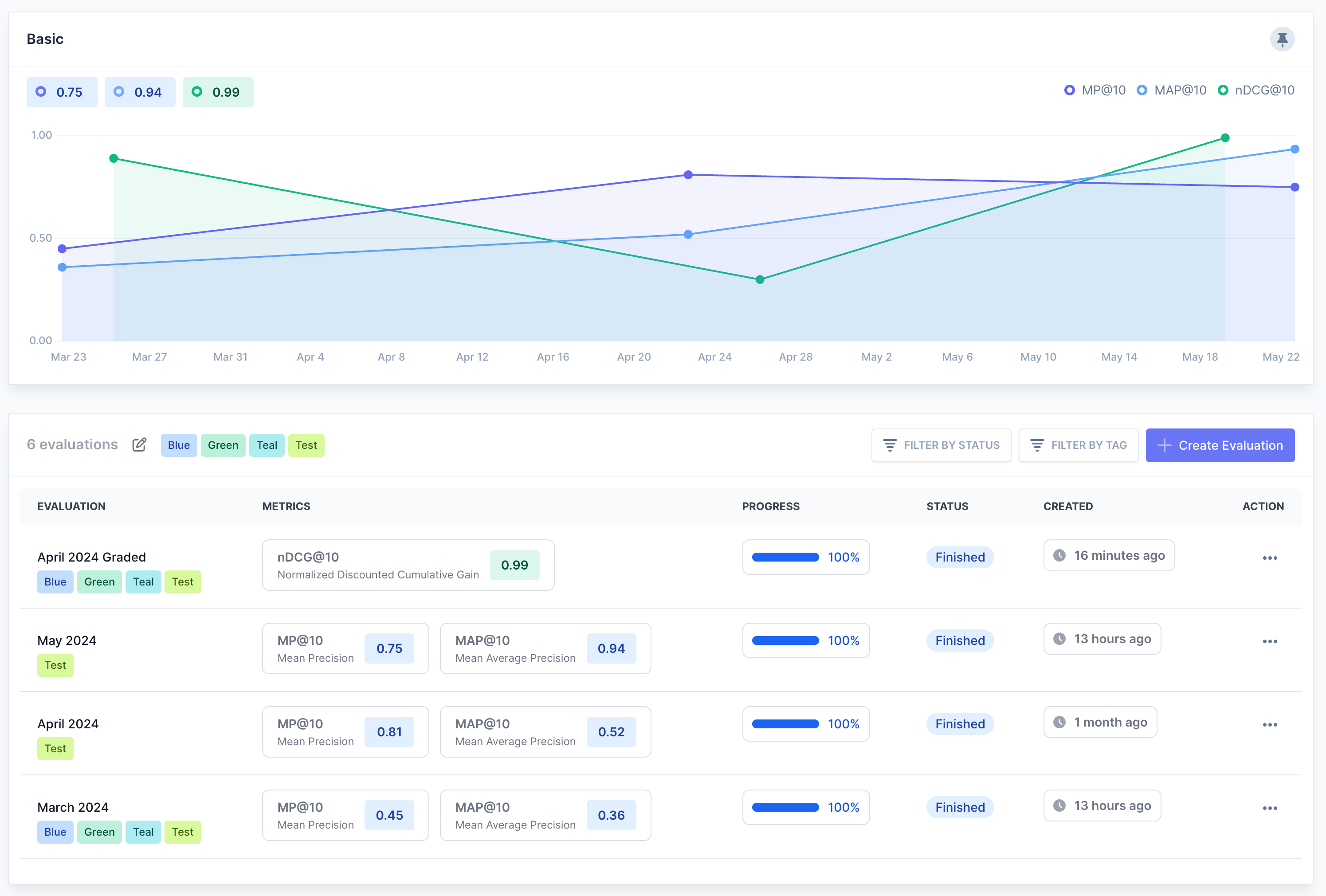
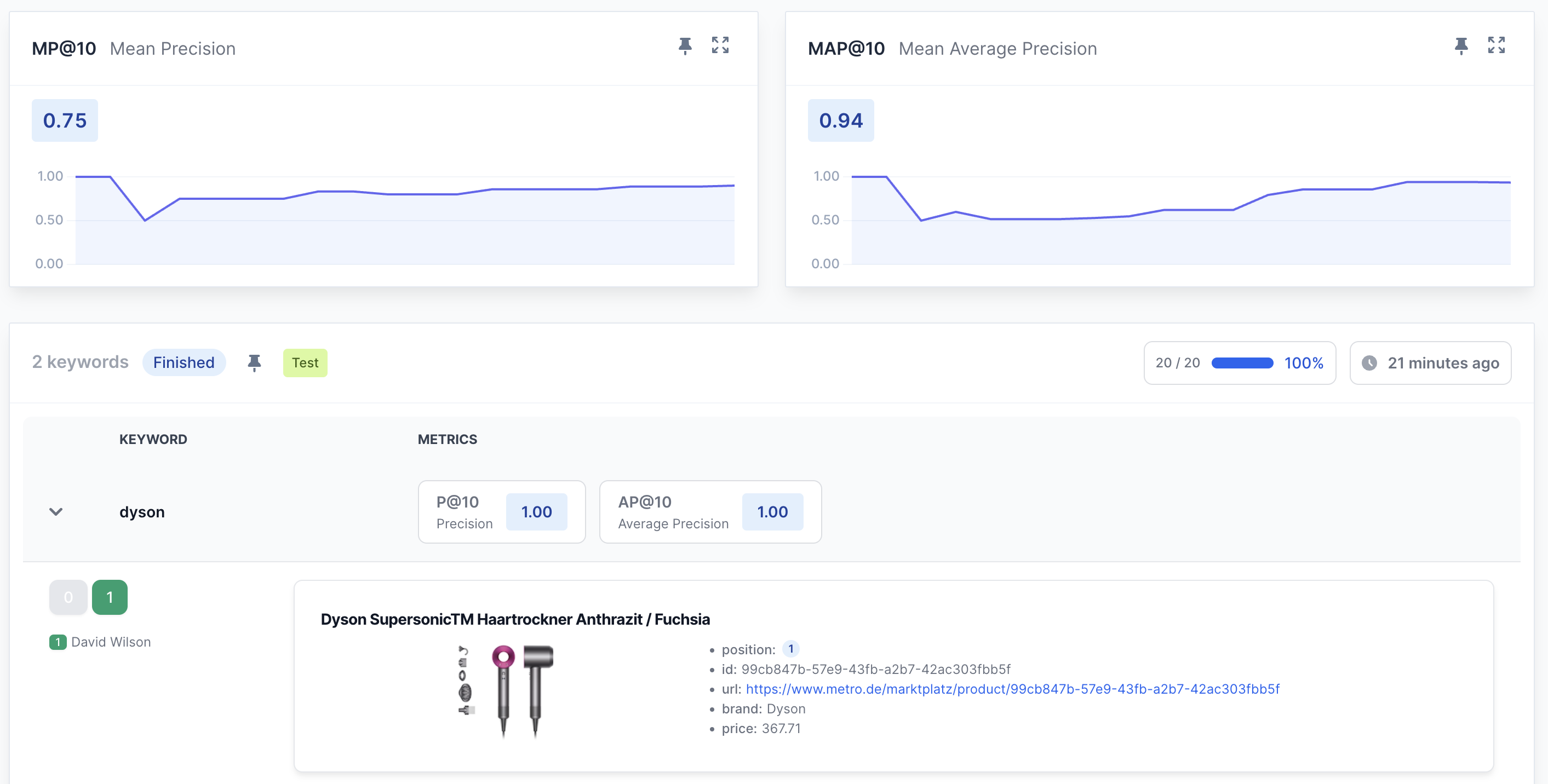
Step 3: Measure & Analyze
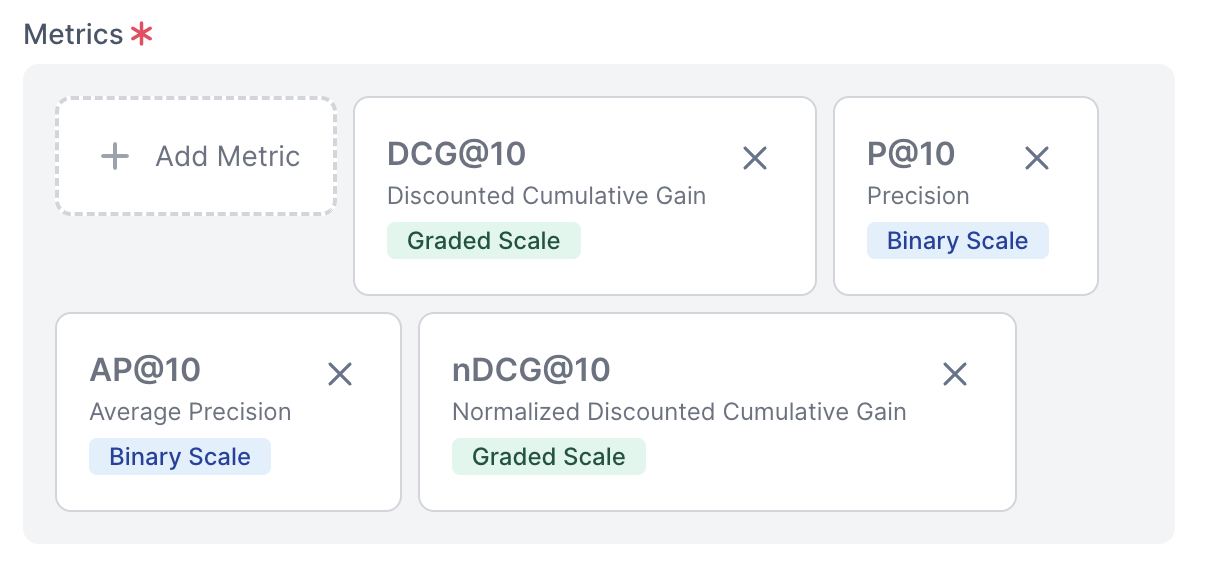
Track metrics that actually matter
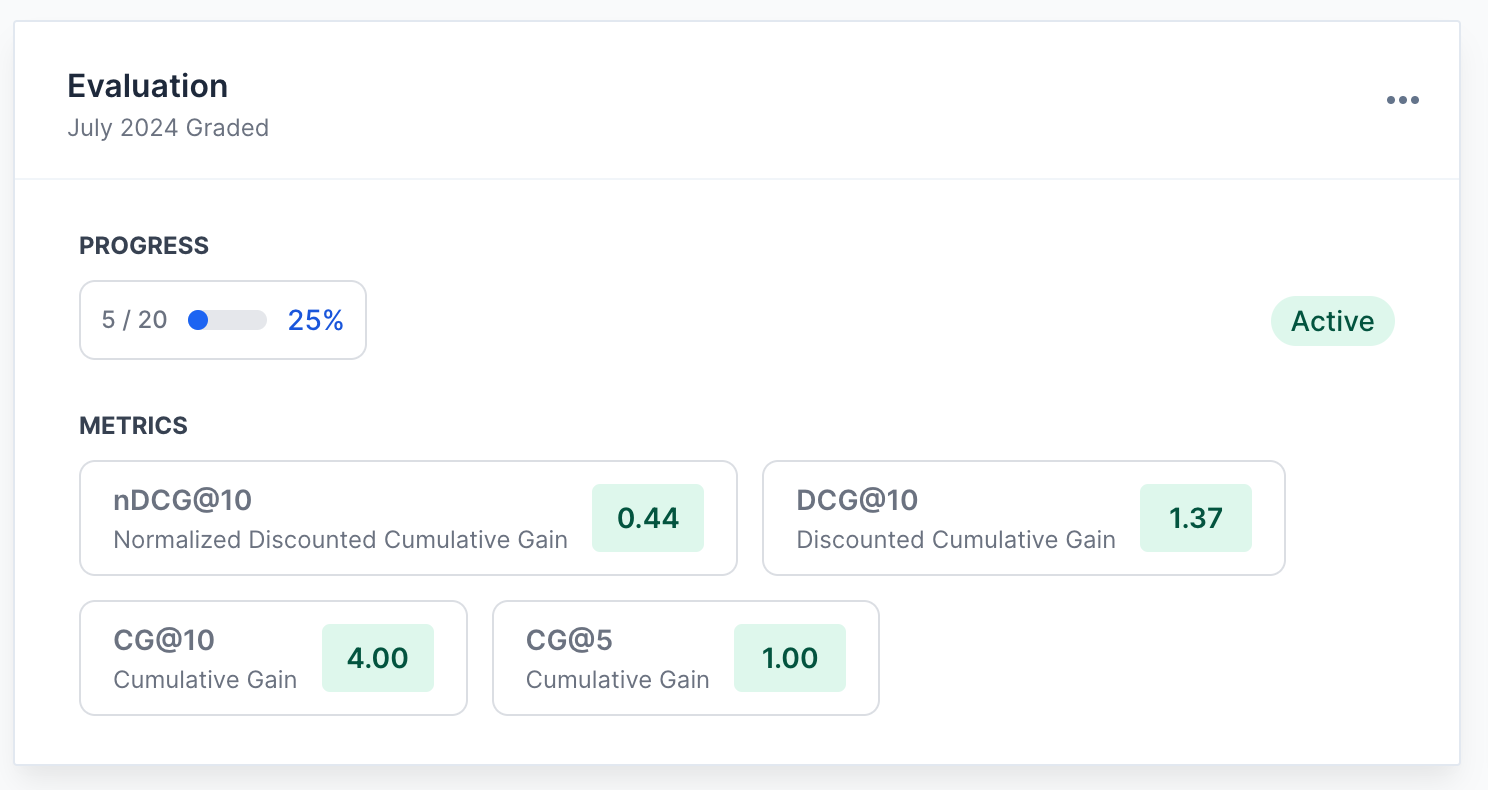
Stop flying blind. Compare your production model against a new experiment before running costly A/B tests. Track NDCG, MAP, and Precision across multiple test endpoints in real time.
- P@10 (Precision)
- MP@10 (Mean Precision)
- AP@10 (Average Precision)
- MAP@10 (Mean Average Precision)
- RR@10 (Reciprocal Rank)
- MRR@10 (Mean Reciprocal Rank)
- CG@10 (Cumulative Gain)
- DCG@10 (Discounted Cumulative Gain)
- NDCG@10 (Normalized Discounted Cumulative Gain)
Track and improve search performance with a wide range of metrics.
Build LTR datasets in days, not months. Export clean judgment lists to train your own Learning-to-Rank models or run deep analytics.
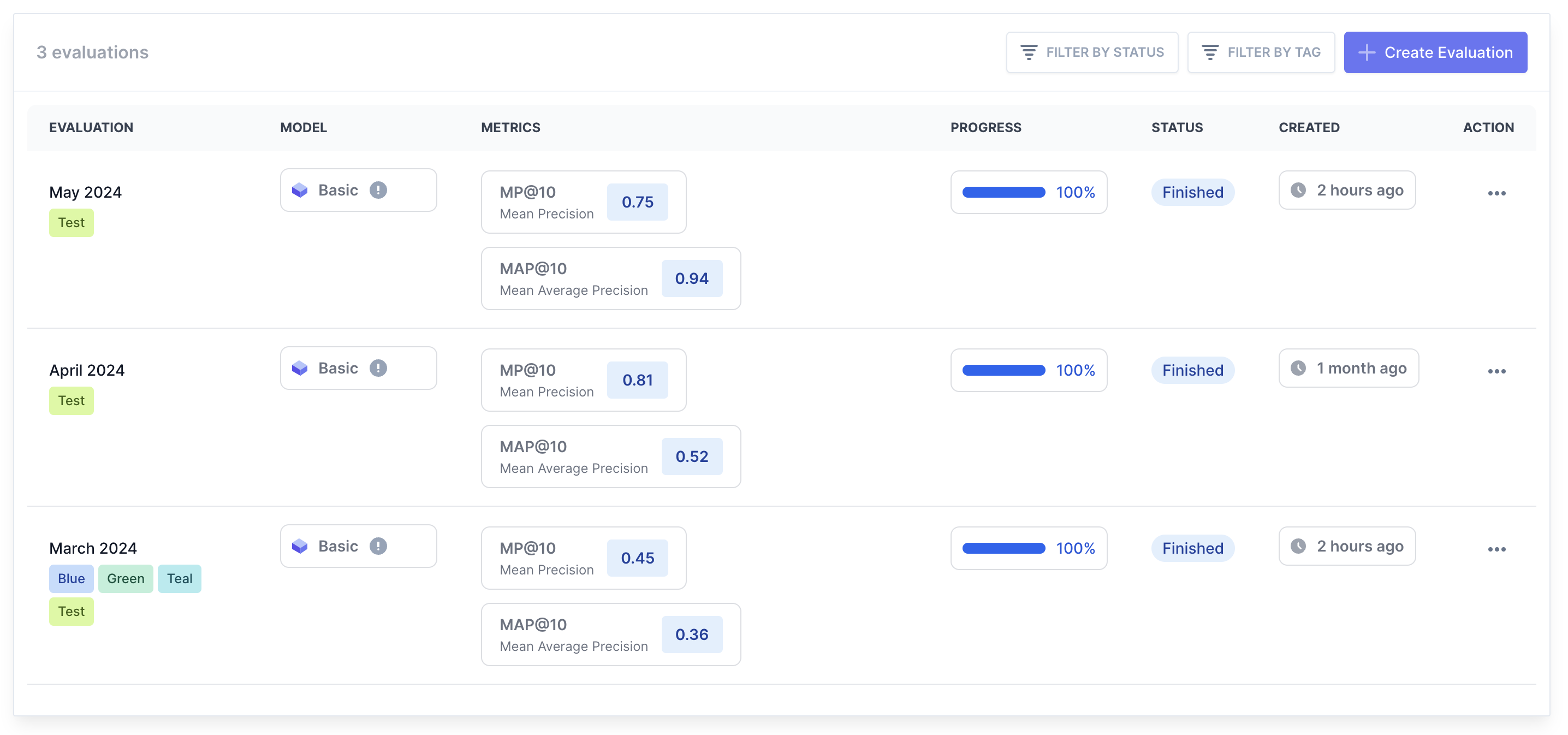
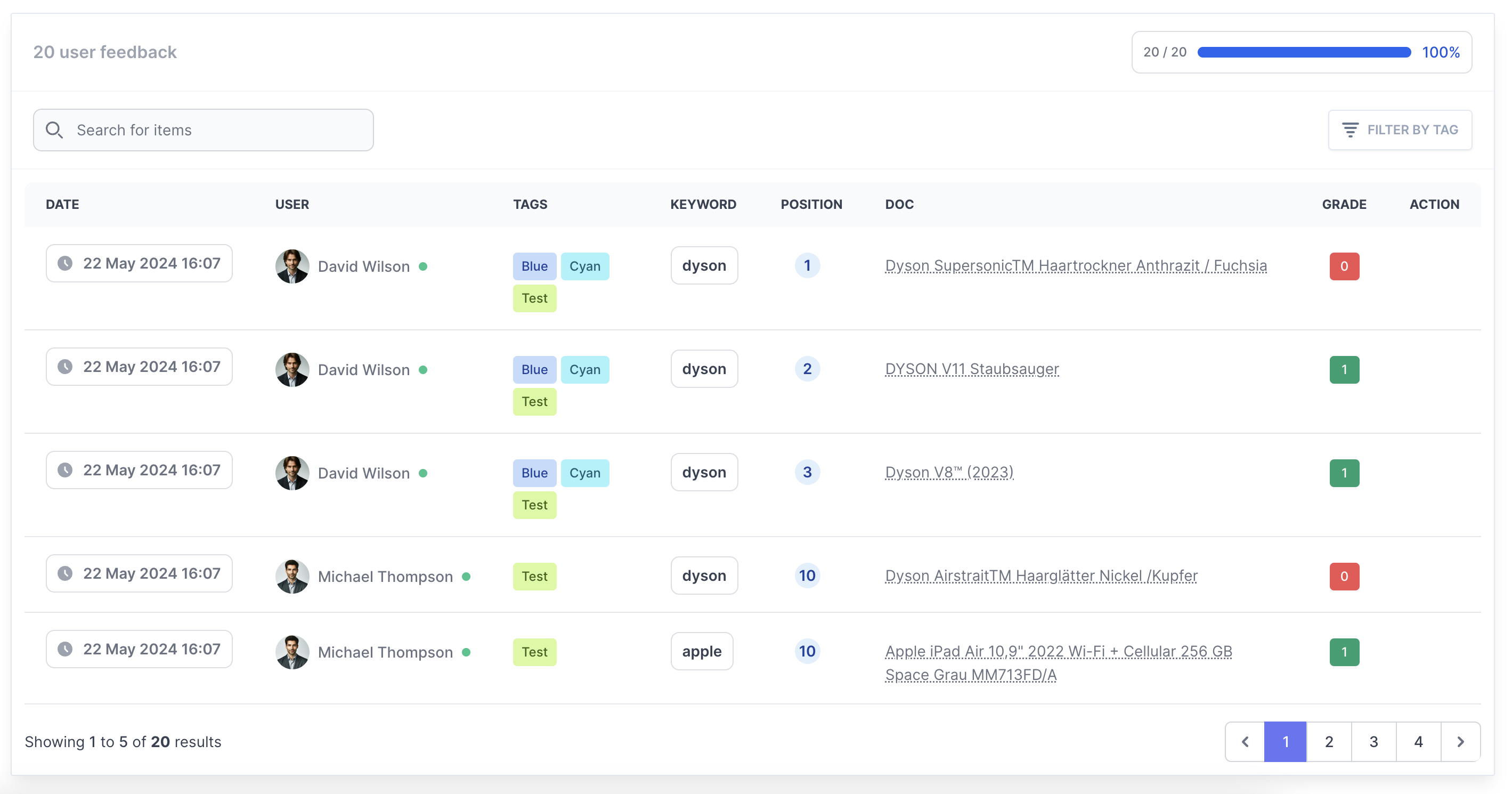
Everything your search team needs to scale
Keep your raters engaged
Eliminate spreadsheet fatigue. Manage human raters with intuitive keyboard shortcuts, progress bars, and localized leaderboards.
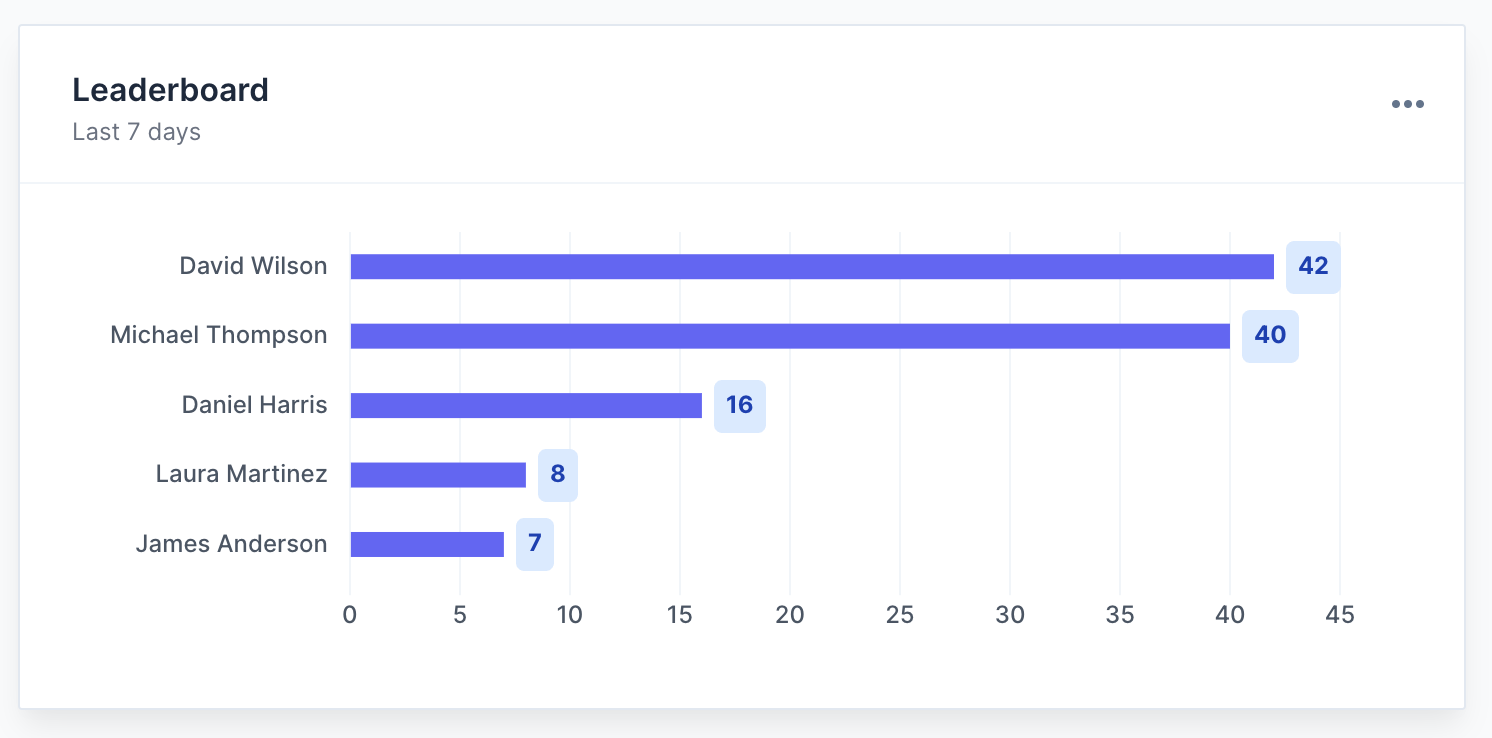
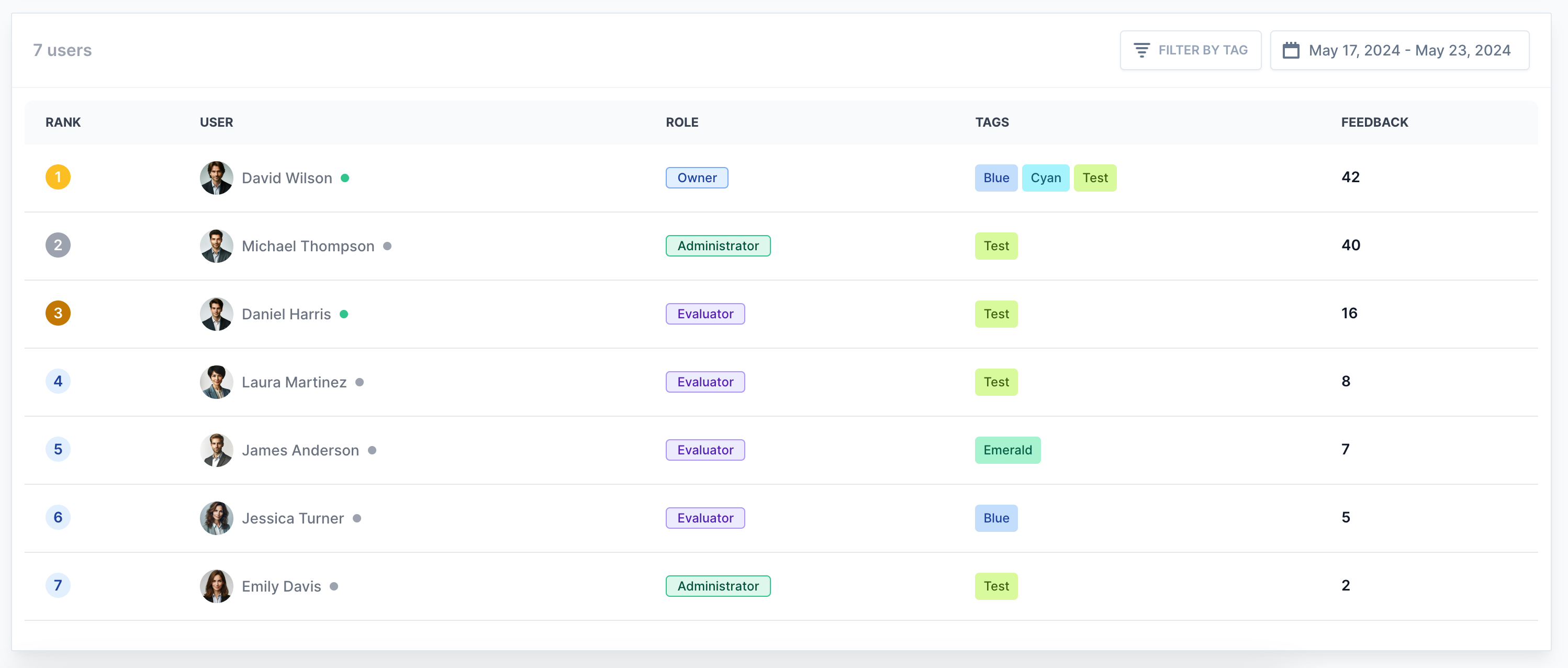
Search evaluator leaderboards
Motivate and recognize top evaluators with leaderboards that showcase the best performing team members based on their evaluation contributions.
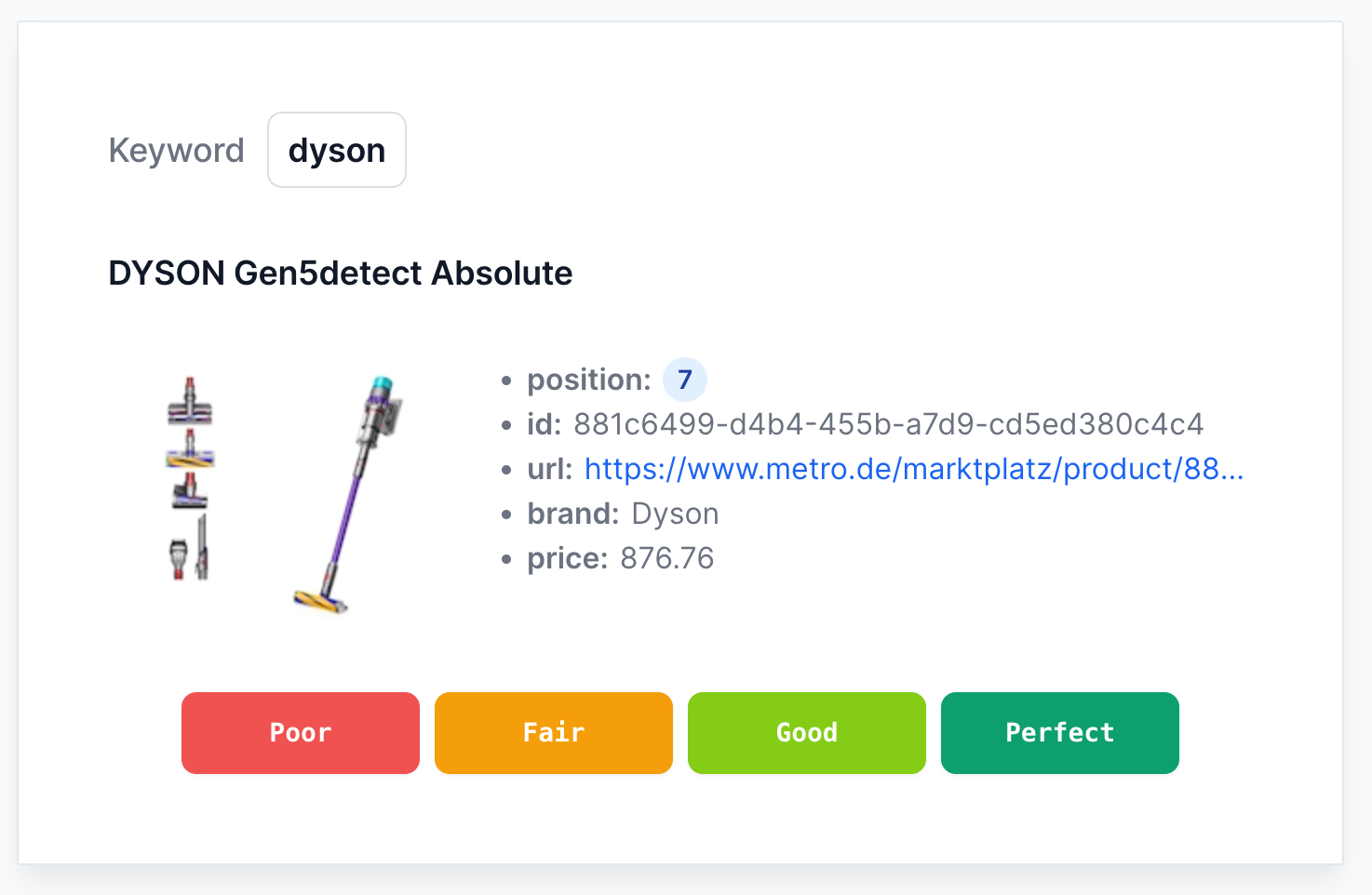
Intuitive search evaluator interface
Enjoy an easy-to-use, attractive interface designed for efficient and effective search evaluation.
Customizable dashboard widgets
Personalize your dashboard with widgets that display the most relevant data and insights for your needs.
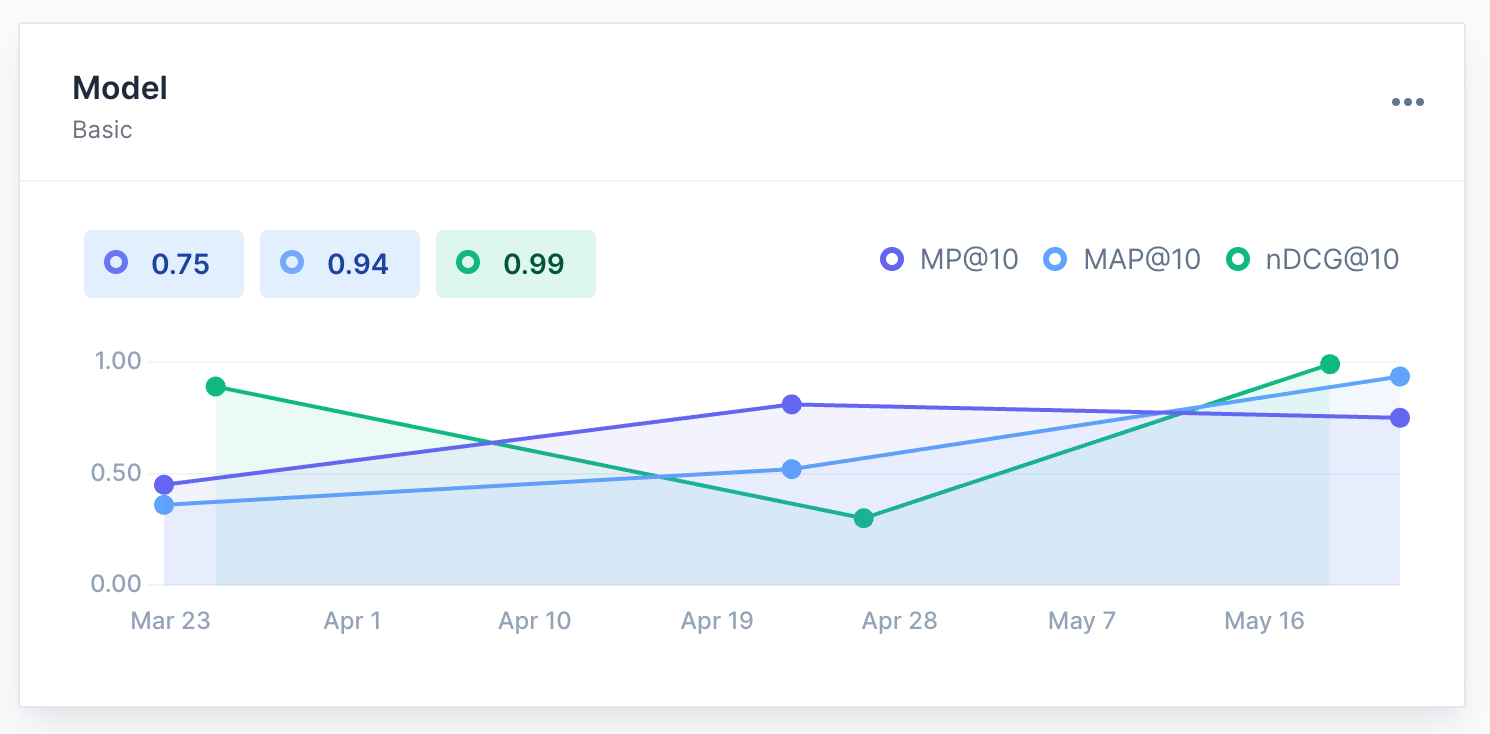
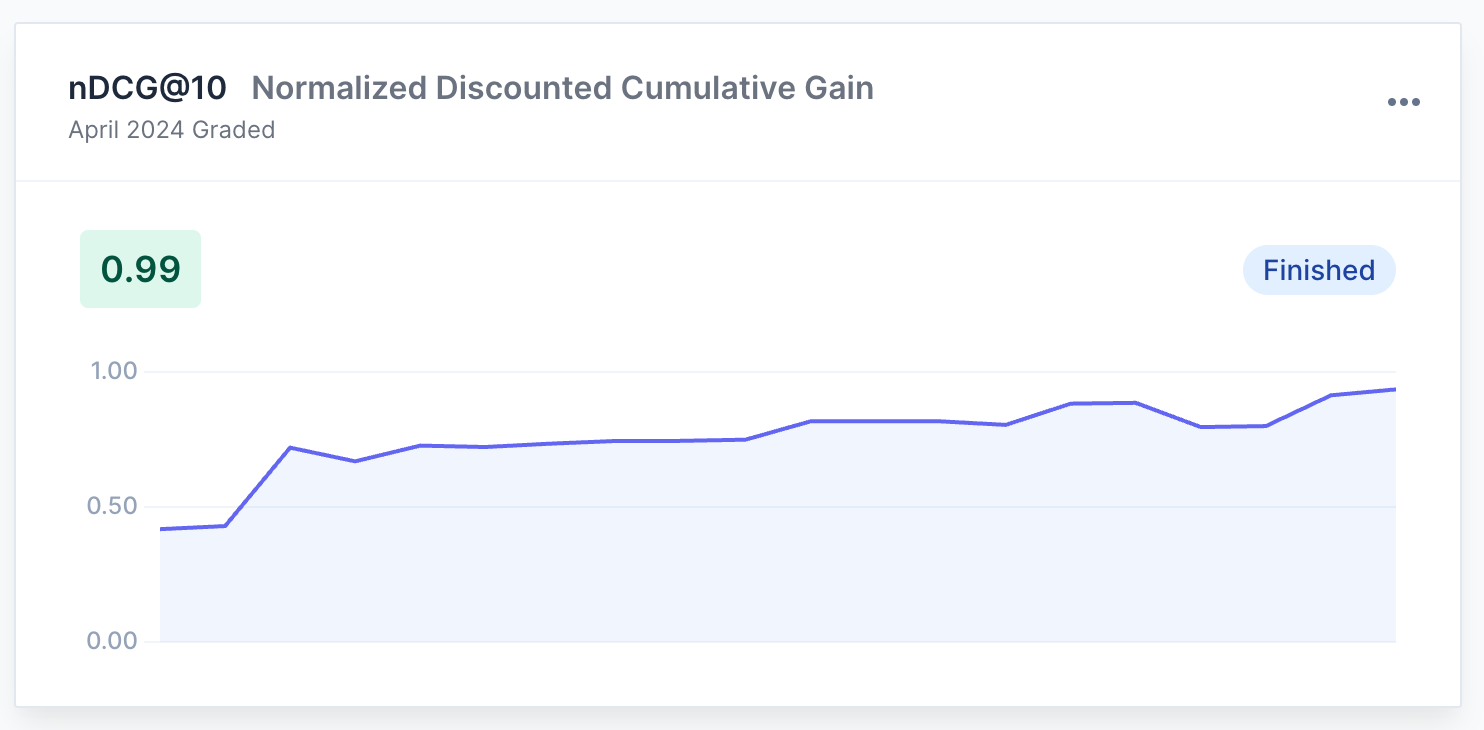
Progress and evaluation graphs
Visualize your search evaluation progress. Monitor improvements and identify areas for further optimization.
Embed it in your data pipeline
REST API makes it easy to make it a part of your data pipeline and integrate it with your existing tools and services.
- 10x
- Faster ranking iterations
- Zero
- Scripts required
- 100%
- Data ownership (Open-Source)
"SearchTweak cut our ranking experimentation cycle from weeks to days. Having AI judges validate changes before we send them to human raters saved us countless hours and significantly improved our NDCG."

Designed for search teams like yours
Choose the plan that fits your search evaluation needs. Simple, transparent pricing.
Open Source
Self-hosted for teams needing total data control
- Unlimited evaluations & models
- Unlimited team members
- REST API included
- Requires self-hosting
Cloud Starter
Best for solo developers and quick evaluation tests
- Team size: 1 member
- Endpoints: up to 2
- Models: up to 5
- Keywords: up to 50 / eval
- AI Judges: up to 1 (BYOK)
- Data Retention: 30 days
Cloud Team
Best for growing teams and mid-sized organizations
- Team size: up to 10 members
- Endpoints: up to 10
- Models: up to 50
- Keywords: up to 1,000 / eval
- AI Judges: up to 5 (BYOK)
- REST API included (CI/CD)
- Data Retention: 1 year
Cloud Enterprise
Best for large teams and organizations with advanced needs
- Unlimited team members
- Unlimited endpoints & models
- Unlimited keywords
- Unlimited AI Judges (BYOK)
- REST API included (CI/CD)
- Data Retention: Unlimited
- Priority Support & Setup Assistance
Frequently asked questions
Search Tweak is a relevance evaluation platform for search and recommendation systems. It combines human judgments, LLM-as-a-Judge (AI Judges), experiment tracking, and quality metrics in one workflow, so teams can ship ranking improvements faster and with more confidence.
Yes! Finding the right context in RAG is essentially a search problem. SearchTweak is perfect for evaluating the "Retrieval" phase of your GenAI applications using metrics like NDCG and AI Judges.
Yes, all API keys for AI judges are securely encrypted in the database at rest and are never sent to the client side. Plus, with the Open Source edition, you can self-host and keep your data 100% under your control.
Yes. You can integrate Elasticsearch-compatible APIs or any custom search service by configuring URL, method, headers, request payloads, and result mapping logic in the UI.
Search Tweak also provides a REST API, allowing you to automate evaluations, push judgments, and trigger AI Judges directly from your CI/CD pipelines.
Yes. You can export human judgments and AI Judge results (including JSONL formats) for training pipelines (Learning to Rank), offline evaluation, internal analytics, or audit workflows.
You create an AI Judge with a scoring scale and prompt template, select an LLM provider, and run it on your evaluation queries. Search Tweak stores labels and reasoning so you can compare AI vs human judgments.
Best practice: Use AI Judges for large-scale, fast iteration and cost-efficient first-pass labeling. Keep humans in the loop for calibration, edge cases, and final quality gates. Monitoring AI vs Human agreement rates helps continuously refine your prompts.
Search Tweak supports OpenAI-compatible endpoints and major providers including Anthropic, Gemini, DeepSeek, Groq, xAI, and Ollama. You can configure model parameters, prompts, and output validation per judge.
Absolutely. SearchTweak supports Ollama and any Custom OpenAI-compatible endpoints. This means your private search data doesn't have to leave your internal network when using local LLMs as judges.
You bring your own API keys (BYOK), which means you have complete transparency over costs and pay the LLM provider directly for the tokens you use. SearchTweak displays token usage per evaluation so you can easily forecast expenses.
The Cloud Starter package is best for trying Search Tweak alone and tests the core workflow. The Team and Enterprise packages unlock larger teams, API automation (for CI/CD), and higher volume limits.
We chose Functional Source License 1.1 (FSL-1.1-Apache-2.0) to balance openness and long-term product sustainability. It allows teams to use, modify, and self-host Search Tweak while protecting against direct commercial clones.
After two years, it converts to Apache 2.0. This gives the community a clear path to a permissive license while keeping the project commercially viable today.
Learn more about our licensing choice on the Functional Source License website.